Posts Tagged ‘Python’
Hunspell
Hunspell розшифровується як “угорський правопис”, і це найбільш просунута програма перевірки правопису якщо не враховувати Grammarly. А все тому що угорська мова – найбільш скажена в плані морфології. Тому якщо щось підходить для угорської – для інших європейських мов точно підійде.
sudo apt install hunspell hunspell-uk hunspell-de-de libhunspell-dev
sudo pip install hunspell
hunspell має доволі простий інтерфейс для використання в мовах програмування (хоча й складні словники (читати man hunspell.5)):
>>> import hunspell
>>> spellchecker = hunspell.HunSpell('/usr/share/hunspell/uk_UA.dic', '/usr/share/hunspell/uk_UA.aff')
>>> spellchecker.spell('ласка')
True
>>> spellchecker.spell('ласкає')
False
>>> spellchecker.suggest('ласкає')
['ласка', 'ласкам', 'лускає', 'ласках', 'ляскає', 'ласка є', 'скалатає']
Скільки слів треба щоб написати вікіпедію? І які зустрічаються частіше?
Виявляється відтоді як я рахував символи вікіпедії пройшло вже більше року. Рахував я їх за допомогою Go, хоча можна було сильно спростити собі життя і рахувати їх за допомогою Python і pywikipediabot. Сьогодні розкажу як, і як можна побачити з назви – рахуватимемо слова.
Я чомусь боявся що щоб порахувати слова пам’яті не вистачить, тому треба якусь базу даних. Або пробувати все в пам’яті, але аби комп’ютеру не стало погано якось обмежити доступну пам’ять. Але мої 4Gb використовувались лише щось трохи більше ніж на 40% для підрахунку всіх слів включно зі сторінками обговорень, категорій, шаблонів, сторінок опису файлів, і т.п. німецької вікіпедії.
В модулі pywikibot.pagegenerators є об’єкти XMLDumpOldPageGenerator і XMLDumpPageGenerator. Вони приймають назву архіву з XML дампом в конструкторі, а після створення по них можна ітеруватися отримуючи об’єкти сторінки. Не ведіться на слово “Old” в назві першого об’єкта, це означає не депрекацію, а те що текст сторінки буде братись з дампа, а в другому випадку з дампа буде братись лише заголовки, а за свіжим текстом зроблять запит, що сповільнить обробку разів в 500. Тобто замість кількох годин ви будете чекати рік. 🙂
Я спробував проаналізувати німецьку вікіпедію (код буде пізніше), на це пішло 694 хв (трохи менше ніж 12 годин) і вийшло що в ній на 6,425,028 сторінках використовується 2,381,457,397 слів (приблизно 371 на сторінку), з них різних слів 18,349,393. В кінцевому результаті CSV з частотним словничком виходить на 300MB.
Серед тих що зустрічаються лише раз є слова типу PikettdienstPikettdienst (помилка парсера який видаляв розмітку), слово – це юридичний термін швейцарської німецької і перекладається як “служба за викликом”. І є слова на зразок Werkshöfe – подвір’я фабрик.
Топ 50 слів виглядає так, і складає 28% всіх слів загалом:
| der | 58761447 | sich | 9169933 |
| und | 49084873 | wurde | 9114619 |
| die | 44536463 | CET | 8614461 |
| in | 35684744 | an | 8385637 |
| von | 24448221 | er | 7835324 |
| ist | 20614114 | dass | 7550955 |
| den | 19454023 | du | 7435099 |
| nicht | 17519638 | bei | 7420172 |
| das | 17302844 | Diskussion | 7237855 |
| zu | 16167971 | aus | 7065523 |
| mit | 15906145 | Artikel | 6967243 |
| im | 15167140 | oder | 6824420 |
| des | 14661593 | werden | 6508092 |
| für | 14016308 | war | 6449858 |
| auf | 13957013 | nach | 6426826 |
| auch | 12849476 | wird | 6117566 |
| eine | 11903977 | aber | 6052645 |
| ein | 11780352 | am | 6017703 |
| Kategorie | 11369651 | sind | 5953632 |
| als | 11167157 | Der | 5623930 |
| dem | 11124726 | Das | 5545595 |
| CEST | 11104741 | einen | 5465687 |
| ich | 10886406 | noch | 5409154 |
| Die | 10761776 | wie | 5293658 |
| es | 10204681 | einer | 5228368 |
До списку потрапили такі вікіпедійно специфічні слова як Kategorie (сторінки без категорій вважаються не комільфо), CEST і CET (центральноєвропейський літній час і центральноєвропейський час, в підписах в обговореннях).
Ну а що без сторінок обговорень? Проблемав тому, що при створенні об’єкту сторінки XMLDumpOldPageGenerator бере з дампа лише текст і заголовок, простір імен залишається не заповненим і за замовчуванням 0 (основний). Є ще поле isredirect так при спробі доступу до нього знову здійснюється запит. Тому, краще перейти на рівень нижче і використати XmlDump з pywikibot.xmlreader, він використовується так само, просто дає об’єкти не Page, а попростіші, які не вміють робити запити до вікіпедії і не мають методу save. Але нам його й не треба, правда?
Ось код який ігнорує перенаправлення і всі сторінки крім статтей:
"""Count word frequencies in wikipedia dump"""
import csv
from collections import Counter
from itertools import islice
import re
import sys
import mwparserfromhell
from pywikibot.xmlreader import XmlDump
def main():
"""Iterate over pages and count words"""
if len(sys.argv) < 2:
print('Please give file name of dump')
return
filename = sys.argv[1]
pages = 0
words = 0
words_counts = Counter()
print('Processing dump')
for page in XmlDump(filename).parse():
if (page.ns != '0') or page.isredirect:
continue
try:
text = mwparserfromhell.parse(page.text).strip_code()
except Exception as e:
print(page.title, e)
continue
text = text.replace('\u0301', '') # remove accents
# Ukrainian:
# page_words = re.findall(
# r'[абвгґдеєжзиіїйклмнопрстуфхцчшщьюя'
# r'АБВГҐДЕЄЖЗИІЇЙКЛМНОПРСТУФХЦЧШЩЬЮЯ’\'-]+',
# text
# )
# Any language:
page_words = re.findall(r'\b[^\W\d]+\b', text)
pages += 1
words += len(page_words)
words_counts.update(page_words)
if pages % 123 == 0:
print('\rPages: %d. Words: %d. Unique: %d. Processing: %s' % (
pages, words, len(words_counts), (page.title + ' ' * 70)[:70],
), end='')
print('Done. Writing csv')
with open('common_words.csv', 'w', newline='') as csvfile:
csvwriter = csv.writer(csvfile)
for item in words_counts.most_common():
csvwriter.writerow(item)
if __name__ == '__main__':
main()
Він працює майже вдвічі швидше, 381 хвилину, бо обробляє лише 2,295,426 сторінок (обсяг німецької вікіпедії цього року). На цих сторінках є 1,074,446,116 слів (в середньому 468 на сторінку), з них різних – 12,002,417. (Виявляється є аж 6 мільйонів всяких слів які вживаються на всіляких службових сторінках німецької вікіпедії, і яких нема в статтях).
Якщо ж взяти українські статті, то на них треба ще менше часу – 131 хвилину (забув уточнити що в мене SSD), їх є 923238 (скоро мільйон!), слів 238263126 (в середньому 258 на сторінку, треба доповнювати 😉 ). З них різних – 4,571,418. Отак, в мене тепер є частотний словник української на 4.5 мільйони слів. І німецької на 12 мільйонів.
Хоча не спішіть з висновками що українська мова бідніша, бо мої методи потребують вдосконалення. По перше, так як Morgen (ранок) і morgen (завтра) – різні слова, то я не приводив букви в німецькій до одного регістру. (Правда й в українській забув це зробити).
По друге, в німецькому словнику 350590 разів зустрічається слово “www”, бо я вважав словом будь-яку послідовність літер латинки, а в українській відфільтрував кирилицю. Слово youtube зустрічається 8375 разів, а значить є ризик знайти якесь рідкісне слово на зразок “fCn8zs912OE”. 🙂
На WordPress глючить додавання картинок, тому нате вам відео:
А, і ось топ-10 української вікіпедії:
в,4551982
на,3730686
і,3475086
у,3353796
з,3053407
-,2695783
Категорія,2417267
та,2350573
до,1815429
року,1553492
Частота “року” наводить на думку що в українській вікіпедії якийсь перекос на історичні методи викладу. 🙂
Docker і обмеження ресурсів
Раніше я вже писав собі шпаргалку по докеру, яка нікому крім мене майже не потрібна, тут буде додаток до неї.
Контейнери докера – це аналог процесів в ОС – тобто щось що запущено виконується. Запускаються імеджі (аналог виконуваної програми). Можна взяти готовий імедж, можна зробити свій за допомогою докерфайла (аналог коду програми), який описує як білдиться (аналог компіляції) імедж.
Загалом команда запуску контейнера виглядає так:
docker run $image_name [$command]
Наприклад якщо цікаво виконати якийсь код на останньому Python, але лінь його ставити, докер скачає і виконає:
docker run python:latest python -c "import sys; print(sys.version)" # Unable to find image 'python:latest' locally # latest: Pulling from library/python # 22dbe790f715: Pull complete # ... # 61b3f1392c29: Pull complete # Digest: sha256:c32b1a9fb8a0dc212c33ef1d492231c513fa326b4dae6dae7534491c857af88a # Status: Downloaded newer image for python:latest # 3.7.2 (default, Mar 5 2019, 06:22:51) # [GCC 6.3.0 20170516]
Якщо не передавати ніяку команду, контейнер виконуватиме ту що для нього задана за замовчуванням. Наприклад
docker run --name test_python_run python:latest # задаємо контейнеру ім'я щоб не сплутати з іншими: docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d95e1e13e3f2 python:latest "python3" 5 seconds ago Exited (0) 4 seconds ago test_python_run
Бачимо що контейнер запускав команду “python3” але вийшов з неї (бо термінал не приєднався). Щоб увійти в інтерактивну сесію, треба запускати так (-i вроді означає інтерактивно, тобто очікувати на stdin, -t – приєднати до поточного терміналу):
docker run -it python:latest
Тільки через командний рядок багато Python коду не передаш. Тому є два варіанти передати файли в контейнер. Перший – прямо в image, за допомогою dockerfile.
Візьмемо для експерименту такий скрипт що поступово пробує використати все більше й більше пам’яті:
import random
import time
data = []
for i in range(10 ** 6):
data.append(random.random())
if i % 1000 == 0:
print(len(data))
time.sleep(0.25)
Managing memory in Python is easy—if you just don’t care. Документація Theano.
Щоб створити з ним імедж достатньо такого докерфайлу:
FROM python:3.7 COPY script.py ./script.py CMD python script.py
Тепер, щоб створити з нього імедж який називається наприклад memeater (зжирач пам’яті), треба виконати:
docker build -t memeater -f Dockerfile .
А щоб потім запустити цей контейнер:
docker run -t memeater
-t щоб бачити що він пише в stdout.
Далі ми можемо за допомогою команди docker stat спостерігати за тим скільки ресурсів цей контейнер їсть:
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 8a58c19cc93c exp 0.28% 6.02MiB / 10MiB 60.20% 3.17kB / 0B 565kB / 1.01MB 2
Аби він не з’їв всю доступну пам’ять, можна йому обмежити ресурси:
docker run -t --name experiment --memory="10M" --cpus=0.1 memeater
Якщо вискакує повідомлення “WARNING: Your kernel does not support swap limit capabilities or the cgroup is not mounted. Memory limited without swap.”, значить у вас трохи не такий Linux, і обмеження стосуватиметься лише RAM, а не області підкачки. Задати параметр --memory-swap теж не допоможе.
Допоможе – взагалі відключити зберігання сторінок на диск.
docker run -t --name experiment --memory="20M" --memory-swappiness=0 --cpus=0.1 memeater
Якщо отримуєте помилку “docker: Error response from daemon: OCI runtime create failed: container_linux.go:344: starting container process caused “process_linux.go:424: container init caused \”\””: unknown.”, то це тому що обмеження по пам’яті за сильне. В мене при 10M вискакує, при 20 – ні.
Що відбувається коли пам’ять закінчується? Лог закінчується так:
492001 Killed
З цього експерименту можна зробити висновок що Python, запущений в системі з доступною пам’яттю 20 мегабайт може втримати в пам’яті трохи менше ніж пів мільйона чисел з плаваючою крапкою.
Python – калькулятор – 2. Sympy
Намагаюсь тут вивчити матан для функцій багатьох змінних щоб зрозуміти як працюють штучні мережі. Для цього використовую Brilliant.org, такий собі гейміфікований сайт для вивчення математики. І враховуючи те що я там вже за 1200 задач зробив, гейміфікація таки працює.
Задачі там варіюються від “знайди x – ось він”, які можна розв’язувати однією рукою, поки іншою штовхаєш коляску парком. Наприклад:
Капітан Кортевеґ причалив біля пірсу, і його човен здійняв одиночну хвилю. Капітану стало цікаво, погнав за хвилею і на ходу виявив що висота води в залежності від часу і позиції в просторі
описується рівнянням:
Який найбільший порядок похідної в цьому рівнянні?

І ти такий думаєш: “Та ось він!”. Вписуєш відповідь на одну цифру, і переходиш до наступного завдання.
А потім капітан думає як розв’язувати те рівняння. І дають підказку, що розв’язок – це
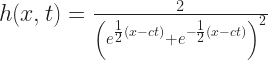
Знайдіть значення c, яке задовольняє вищенаведене рівняння Кортевега – де Фріза.
І ти собі такий, ок, треба знайти кожну похідну, додати і прирівняти до нуля. Добре що дали розв’язок і треба знайти лише константу, бо дифрівняння я все ще не вмію розв’язувати, для того треба вміти інтегрувати. Але все одно без паперу не обійтись. Вдома списую пару листочків:
Прочитати решту цього запису »
Геренуємо пару ключів для цифрового підпису за допомогою RSA в Python
Для тих кому викликати openssl набридло. Це дивно, але цього нема в стандартній бібліотеці python, тому:
sudo pip install pycrypto
Тоді:
from Crypto.PublicKey import RSA
from Crypto import Random
private_key = RSA.generate(1024, Random.new().read)
public_key = private_key.publickey()
print(private_key.exportKey().decode('ascii'))
print(public_key.exportKey().decode('ascii'))
Що дасть нам:
-----BEGIN RSA PRIVATE KEY----- MIICXQIBAAKBgQCFO0e8pxFV5Niq9Kjkn7HpX5xCbsh2oP56t2goNw/qZnddzW1x ... blablabla ... dB6mvhutUqKRZDaA1o4y1kytKTG42RfEtdm8t1Z/77dS -----END RSA PRIVATE KEY----- -----BEGIN PUBLIC KEY----- MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCFO0e8pxFV5Niq9Kjkn7HpX5xC bsh2oP56t2goNw/qZnddzW1xW3rWxYI2/Jxp/hv7EGapg12EcViF/C8Uv2WbCDEM LIRaMqtHKFNaniscMgZKgaohkjXcLk5dIrVXuuxY7sk07BZqj+Jsv6xgR6GZ0CmG Q3ZOmGAKksC/YA3gYwIDAQAB -----END PUBLIC KEY-----
В іншій публікації було показано як це робити допомогою openssl, і як цими ключами підписати токен.